Join my colleagues and myself at this year's Oracle OpenWorld. We have five hands-on lab sessions available to attend. These are all heavily focused on 12c, MySQL, and the new RESTful API for the Oracle ZFS Storage Appliance.

HOL9715 - Deploying Oracle Database 12c with Oracle ZFS Storage Appliance September 29, (Monday) 2:45 PM - Hotel Nikko - Mendocino I/II September 30, (Tuesday) 5:15 PM - Hotel Nikko - Mendocino I/II
HOL9718 - Managing and Monitoring Oracle ZFS Storage Appliance via the RESTful API September 29, (Monday) 2:45 PM - Hotel Nikko - Mendocino I/II October 1, (Wednesday) 10:15 AM - Hotel Nikko - Mendocino I/II
HOL9760 - Deploying MySQL with Oracle ZFS Storage Appliance September 30, (Tuesday) 6:45 PM - Hotel Nikko - Mendocino I/II
The latest release of the ZFS Storage Appliance, 2013.1.1.1, introduces 1MB block sizes for shares. This is a deferred update that can only be enabled inside of Maintenance → System. You can edit individual Filesystems or LUNs from within 'Shares' to enable the 1MB support (database record size).
This new feature may need additional tweaking on all connected servers to fully realize significant performance gains. Most operating systems currently do not support a 1MB transfer size by default. This can be very easily spotted within analytics by breaking down your expected protocol by IO size. As an example, let's look at a fibre channel workload being generated by an Oracle Linux 6.5 server:
Example
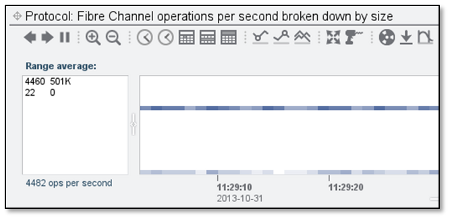
The IO size is sitting at 501K, a very strange number that's eerily close to 512K. Why is this a problem? Well, take a look at our backend disks:
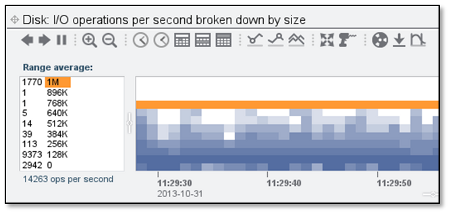
Our disk IO size (block size) is heavily fragmented! This causes our overall throughput to nosedive.
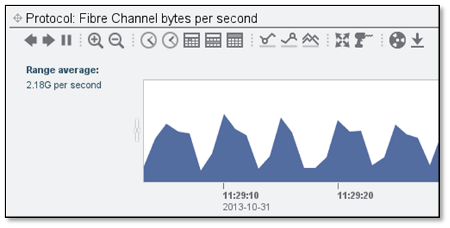
2GB/s is okay, but we can do better if our buffer size was 1MB on the host side.
Fixing the problem
Fibre Channel
Solaris
# echo 'set maxphys=1048576' > /etc/system
Oracle Linux 6.5 uek3 kernel (previous releases do not support 1MB sizes for multipath)
# echo 1024 > /sys/block/dm*/queue/max_sectors_kb
or create a permanent udev rule:
# vi /etc/udev/rules.d/99-zfssa.rules
ACTION=="add", SYSFS{vendor}=="SUN", SYSFS{model}=="*ZFS*", ENV{ID_FS_USAGE}!="filesystem",
ENV{ID_PATH}=="*-fc-*", RUN+="/bin/sh -c 'echo 1024 > /sys$DEVPATH/queue/max_sectors_kb'"
Windows
QLogic [qlfc]
C:\> qlfcx64.exe -tsize /fc /set 1024
Emulex [HBAnyware]
set ExtTransferSize = 1
Please see MOS Note 1640013.1 for configuration for iSCSI and NFS.
Results
After re-running the same FC workload with the correctly set 1MB transfer size, I can see the IO size is now where it should be.
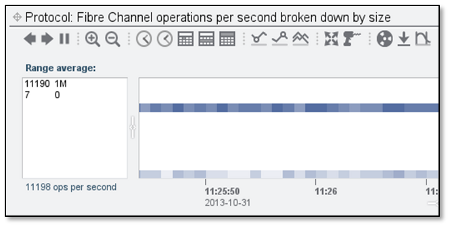
This has a drastic impact on the block sizes being allocated on the backend disks:
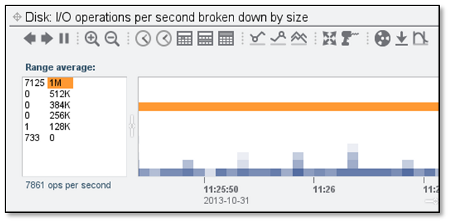
And an even more drastic impact on the overall throughput:
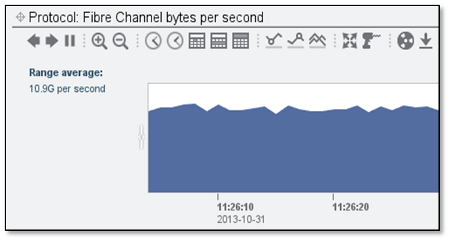
A very small tweak resulted in a 5X performance gain (2.1GB/s to 10.9GB/s)! Until 1MB is the default for all physical I/O requests, expect to make some configuration changes on your underlying OS's.
System Configuration
Storage
- 1 x Oracle ZS3-4 Controller
- 2013.1.1.1 firmware
- 1TB DRAM
- 4 x 16G Fibre Channel HBAs
- 4 x SAS2 HBAs
- 4 x Disk Trays (24 4TB 7200RPM disks each)
- 4 x Oracle x4170 M2 servers
- Oracle Linux 6.5 (3.8.x kernel)
- 16G DRAM
- 1 x 16G Fibre Channel HBA
Workload
Each Oracle Linux server ran the following vdbench profile running against 4 LUNs:
sd=sd1,lun=/dev/mapper/mpatha,size=1g,openflags=o_direct,threads=128 sd=sd2,lun=/dev/mapper/mpathb,size=1g,openflags=o_direct,threads=128 sd=sd3,lun=/dev/mapper/mpathc,size=1g,openflags=o_direct,threads=128 sd=sd4,lun=/dev/mapper/mpathd,size=1g,openflags=o_direct,threads=128 wd=wd1,sd=sd*,xfersize=1m,readpct=70,seekpct=0 rd=run1,wd=wd1,iorate=max,elapsed=999h,interval=1This is a 70% read / 30% write sequential workload.